Multimodal AI Tutor
A real-time AI tutor using vision, speech, and parallel reasoning
Note: This was an internal prototype, so public links are not available.
Multimodal AI Tutor hero image
Timeline
Role
Tools
The Concept
During a Friday “community time” within the BBC AI in Education community, I explored a simple idea:
What if a student could point their camera at a physics problem and ask, “how do I solve this?” and get real-time, voice-based guidance?
The aim was to let students interact naturally with complex problems using their camera and voice and get immediate, step-by-step guidance without any noticeable delay.
My Role
I led the concept, system design, and full-stack implementation. My focus was on validating a low-latency multimodal interaction loop within a short, experimental time frame.
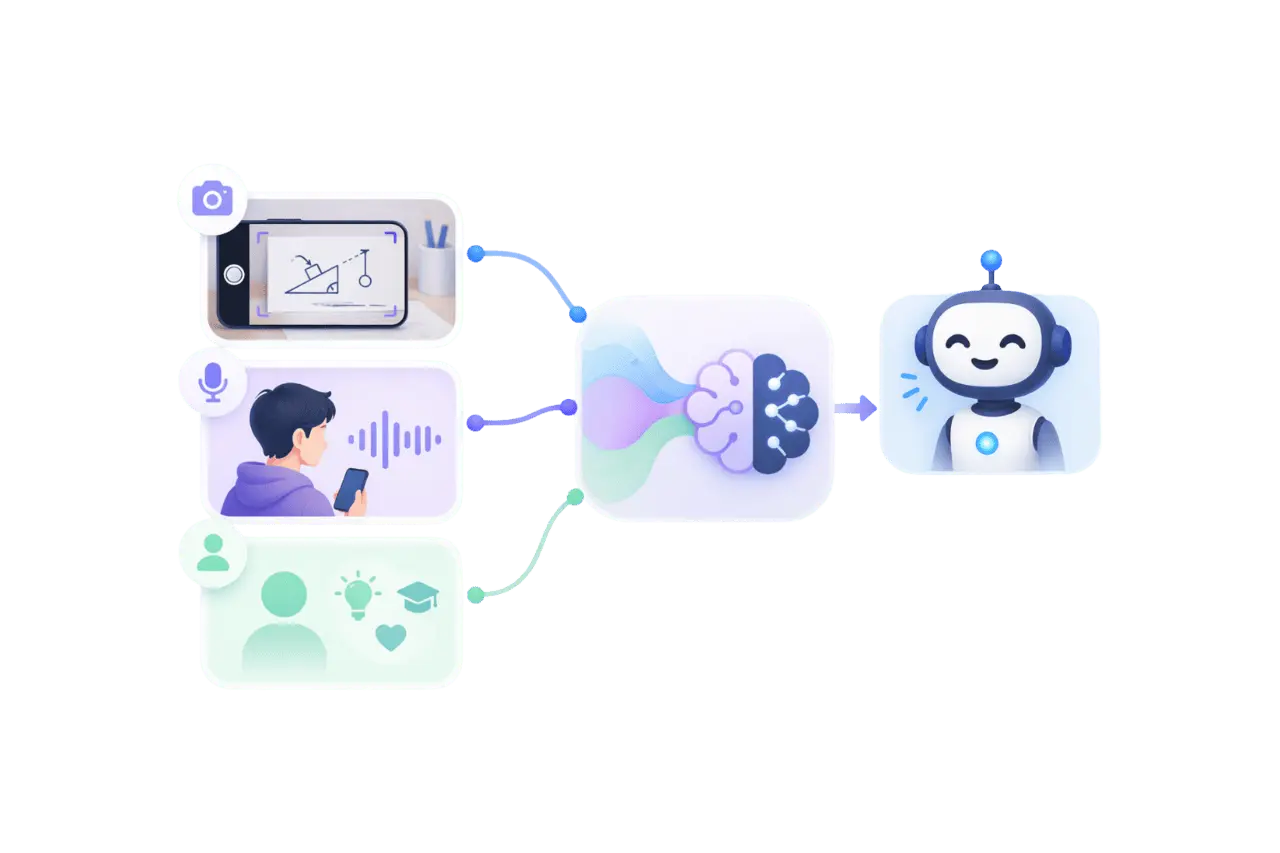
System Architecture
At its core, the system runs on parallel perception and reasoning loops.
Visual context is processed continuously in the background, allowing the tutor to respond instantly when the user speaks.


Figure: High-level System Architecture
The system combines three signals—live visual context, transcribed speech, and a Socratic system persona into a single reasoning step.
By decoupling perception from interaction, it achieves a near real-time experience despite underlying latency.
How It Works
- Visual Context: Low-resolution camera frames are continuously processed to maintain a rolling visual context.
- User Input: Speech-to-text captures user intent and triggers reasoning.
- Multimodal Reasoning: The system combines vision, language, and persona to guide the student.
- Voice Output: Responses are buffered at the sentence level before text-to-speech, ensuring natural delivery.
Key Insight
The breakthrough wasn't raw speed, it was parallelism.
By building context before it was needed, the system felt significantly faster and more responsive than traditional sequential approaches.
Technical Challenges
Outdated Context
Early prototypes suffered from latency—by the time a frame was processed, users had often moved their camera, leading to outdated responses.
I addressed this in two ways:
- Model Speed: Switching to Gemini Flash enabled near real-time image analysis.
- Asynchronous Processing: A background pipeline continuously updates visual context, ensuring recent scene understanding is always available.
By the time the user finishes speaking, the relevant context is already available—making the system feel real-time.
Speech Coherence
Streaming text-to-speech often produced choppy, unnatural output when speaking partial responses in real time.
I implemented a sentence-based buffering system, ensuring only complete sentences were spoken. This introduced minimal delay but significantly improved naturalness and flow.
Outcomes & Learnings
The result was a working end-to-end prototype that could observe a live problem, reason over multimodal context, and respond with coherent voice guidance in near real time. Demonstrating the prototype sparked concrete discussion within the AI in Education community about practical architecture patterns for responsive multimodal tutoring.
The key learning was that perceived responsiveness mattered more than isolated model latency. Parallelising vision and speech made the interaction feel faster and more natural than a sequential request-response flow.